프로세스 외
EST, EFT, Slack Time 구하기
프로젝트 일정 관리(CPM/PERT) 용어 정리
- EST(Earliest Start Time) : 어떤 작업이 가장 일찍 시작할 수 있는 시점 (선행 작업이 모두 끝난 직후)
- EFT(Earliest Finish Time) : 그 작업이 가장 일찍 끝날 수 있는 시점 = EST + 작업 소요 시간
- LST: Latest Start Time (가장 늦게 시작해도 되는 시점)
- LFT: Latest Finish Time (가장 늦게 끝나도 되는 시점)
- Slack Time : 작업 일정의 여유 시간으로 일정 지연이 Slack Time 이내라면 전체 프로젝트 완료일에 영향을 주지 않는다.
다음은 소작업 리스트에서 작업 C의 가장 빠른 착수일, 가장 늦은 착수일, 여유 기간(slack time)을 순서대로 쓰시오.
작업 | 선행작업 | 소요기간 |
A | - | 15 |
B | - | 10 |
C | A,B | 10 |
D | B | 25 |
E | C | 15 |
1. 작업 C의 가장 빠른 착수일 (EST)
EST(Earliest Start Time) : 어떤 작업이 가장 일찍 시작할 수 있는 시점 (선행 작업이 모두 끝난 직후)
작업 C는 A와 B 둘 다 끝난 뒤에 시작 가능하므로 A의 종료 시점인 15일이 C의 EST가 된다.
C의 EST = max(A의 EFT, B의 EFT) = max(15, 10) = 15C의 가장 빠른 착수일이 15일인 이유는, A가 15일에 끝나기 때문이며, C는 A와 B 모두가 완료되어야 시작할 수 있기 때문이다.
2. 작업 C의 LST (Latest Start Time)
LST(Latest Start Time) : 가장 늦게 시작해도 프로젝트 전체 일정에 영향이 없는 착수 시점으로 LST보다 늦게 시작하면 프로젝트 지연이 발생한다.
계산 공식
LST = LFT - 소요 시간- LFT는 Latest Finish Time, 즉 해당 작업이 가장 늦게 끝나야 하는 시점
- 이 시점에 맞춰 끝내려면, 그만큼 거꾸로 거슬러 올라가며 착수해야 함
- → 작업 C는 25일 안에 끝나야 하며, 10일 걸리므로
👉 15일에 시작하면 정확히 25일에 끝난다.
👉 따라서 C의 가장 늦은 착수일(LST)은 15일
3. 작업 C의 Slack Time(슬랙 타임)
Slack Time = LST - EST = LFT - EFT슬랙타임을 구하려면 먼저 Earliest Finish Time (EFT)를 구해야 한다. Slack Time은 Earliest Completion (가장 빠른 완료 시간, 최단 완성 가능 시점)을 기준으로 한다. 이 문제에서는 프로젝트를 가장 빠르게 끝냈을 때 종료 시점인 '40일'을 기준으로 이보다 더 늦게 끝나면 지연이 발생한 것으로 간주한다.
- EFT 계산
- 프로젝트의 가장 빠른 완료 시점(Earliest Completion)은
마지막 작업 E의 EFT = 40일
- 프로젝트의 가장 빠른 완료 시점(Earliest Completion)은
- Slack Time 기준
- 이 40일을 기준으로,
- 작업이 이보다 늦어지면 전체 일정에 지연이 발생했다고 간주한다.
- 작업 C의 Slack 계산
- 작업 C의 EFT = 25일
- 작업 C의 LFT = 25일
- 따라서
Slack=LFT−EFT=25−25=0\text{Slack} = \text{LFT} - \text{EFT} = 25 - 25 = 0Slack=LFT−EFT=25−25=0 - 또는
Slack=LST−EST=15−15=0\text{Slack} = \text{LST} - \text{EST} = 15 - 15 = 0Slack=LST−EST=15−15=0
결론적으로, 작업 C는 Slack Time = 0으로, 전체 프로젝트의 지연 여유가 전혀 없는 Critical Path 상의 작업이다.
프로세스 스케줄링
1. 선점(Preemptive) 스케줄링
선점 스케줄링이란 우선순위가 높은 프로세스가 현재 프로세스를 중지시키고 자신이 CPU를 점유하는 스케줄링 기법
- 실행 중인 프로세스를 중단하고,더 우선순위가 높은 다른 프로세스에게 CPU를 양보
- 비교적 응답이 빠르다는 장점이 있으나, 처리 시간을 예측하기 힘들고 높은 우선순위 프로세스들이 계속 들어오는 경우 오버헤드가 발생하게 된다.
- 선점 스케줄링의 예로는 RR, SRT, 다단계 큐, 다단계 피드백 큐가 있음.
📌 선점 스케줄링 알고리즘
🔹 Round Robin : 시간 할당량(Time Quantum) 지나면 다음 프로세스로 교체
🔹 SRTF (Shortest Remaining Time First) : 남은 시간이 더 짧은 새 작업이 오면 현재 작업 중단
🔹 선점형 우선순위(Priority Scheduling) : 더 높은 우선순위의 프로세스가 도착하면 중단됨
2. 비선점(Non-preemptive) 스케줄링
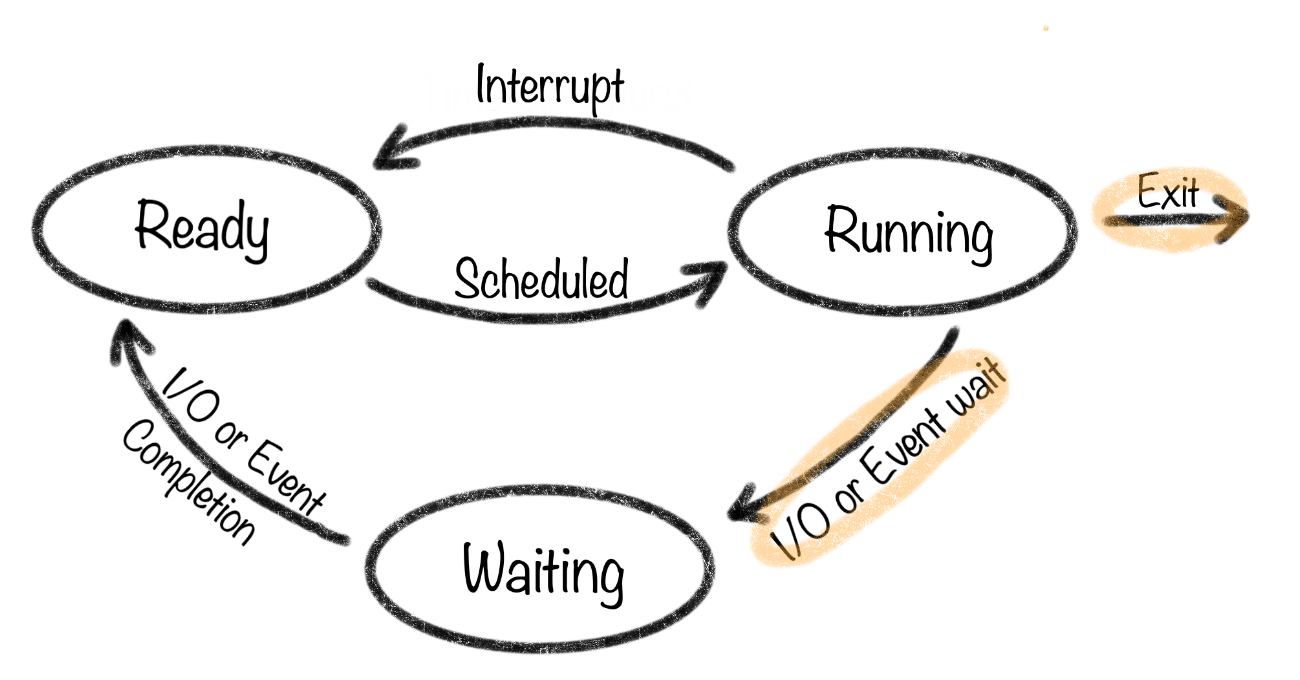
프로세스가 자원을 할당받았을 경우 자원을 스스로 반납할 때 까지 계속 그 자원을 사용하도록 허용하는 기법
한 번 실행된 프로세스는 끝날 때까지 CPU를 점유한다. 그래서 새로 도착한 프로세스는 대기해야 한다.
중요한 작업이 길면, 뒤에 있는 짧은 작업이 오래 기다릴 수 있기 때문에 기아현상 발생 가능
📌 비선점 스케줄링 알고리즘
🔸 FCFS (First Come First Serve) : 먼저 도착한 순서대로 실행
🔸 SJF (Shortest Job First) : 실행시간이 짧은 것부터 실행
🔸 비선점 우선순위 스케줄링 : 우선순위 높은 순으로 실행, 중간 교체 없음
🔸 HRN (Highest Response Ratio Next) : 반응 비율 기반, 대기시간 고려
문제풀이
비선점은 들어온 순서대로 처리하니까 쉬움
선점형은 실행 도중에도 더 짧은 프로세스가 도착하면 현재 작업을 중단하고 짧은 걸 먼저 실행하므로실행 순서가 바뀜
1.FCFS
- 난이도 ⭐
- 도착한 순서대로 처리하면 됨

- 최소 평균 반환시간 t 는 실행시간이 짧은 것부터 실행 (P2 → P1 → P3)
- t = ( 0 + 3 + 12 ) / 3 = 15 / 3 = 5
- 최대 평균 반환시간 T 는 실행시간이 긴 것부터 나열 (P3 → P1 → P2)
- T = (0 + 12 + 21) / 3 = 33 / 3 = 11
- T - t = 11 - 5 = 6
2.SFJ
- 난이도 ⭐
- 실행시간 짧은 것부터 실행하면 됨
- 평균대기시간 / 평균반환시간 / 평균실행시간 중 무엇을 구해야 하는지 확인
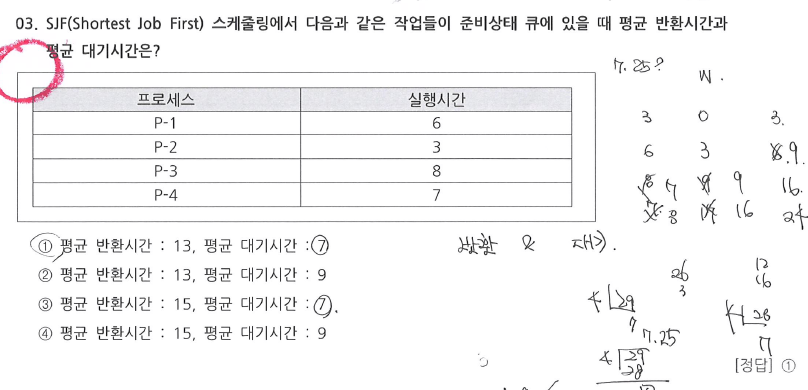
프로세스 | 실행시간 | 대기시간 | 반환시간 |
P-2 | 3 | 0 | 3 |
P-1 | 6 | 3 | 9 |
P-4 | 7 | 9 | 16 |
P-3 | 8 | 16 | 24 |
|
| 28 / 4 = 7 | 52 / 4 = 13 |
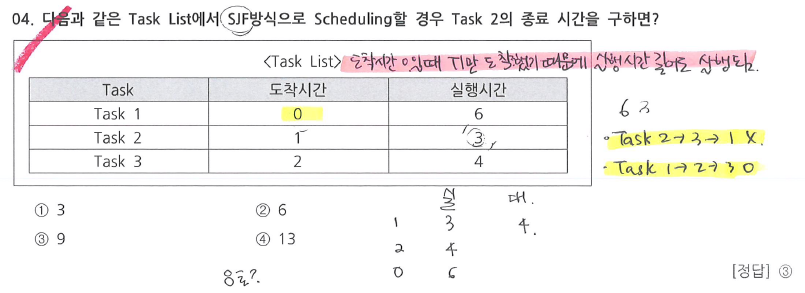
Task | 도착시간 | 실행시간 | 대기시간 | 반환시간 |
Task1 | 0 | 6 | 0 | 6 |
Task2 | 1 | 3 | 6 | 9 |
Task3 | 2 | 2 | 9 | 2 |
합계 |
|
| 15 | 17 |
- Task2의 반환시간 = 2의 대기시간(Waiting Time) + 2의 실행시간(Burst Time) = 6 + 3 = 9
⭐ 도착시간이 0일 때 T1만 도착했기 때문에 T1가 실행시간이 길더라도 먼저 실행된다. (왜? 해당 시간에 도착한 작업이 T1뿐)
3.HRN
- 난이도 ⭐
- 비선점 스케줄링 알고리즘 중 하나로, 대기시간이 길어질수록 우선순위가 높아지는 방식
- 우선순위 = 1 + 대기시간/서비스 시간
- → 숫자가 클수록 우선순위가 높다!
✅ HRN 우선순위 계산식

- 대기시간 (Waiting Time) = 현재 시점 − 도착시간 − 아직 실행 안 된 경우
- 서비스시간 (Service Time) = 실행시간, 즉 Burst Time
- 짧은 작업(SJF)에게 유리하면서도,오래 기다린 작업도 점점 우선순위가 높아져 기아 현상(starvation) 방지 가능!
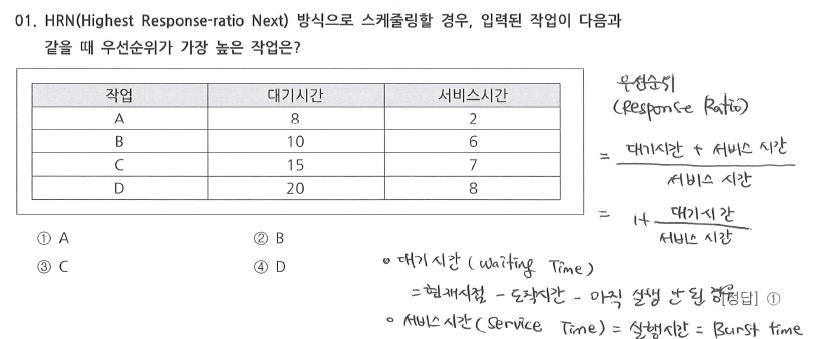
- A = 1 + (8 / 2) = 1 + 4 = 5
- B = 1 + (10 / 6) = 2.6666
- C = 1 + (15 / 7) = 3.14
- D = 1 + (20 / 8) = 3.5
- 우선 순위 큰 순서대로 A > D > C > B
4.SRT
- 난이도 ⭐⭐
- SRT(Shortest Remaining Time First)는 선점형 프로세스 스케줄링 알고리즘 방식
- 현재 실행 중인 프로세스보다 남은 실행시간이 더 짧은 새로운 프로세스가 도착하면 CPU를 양보하기
- 그래프 그리면서 풀기
- 반환시간 = 종료시간 - 도착시간


5.RR(Round Robin)
- 난이도 ⭐⭐⭐
- 타임 퀀텀 (Time Quantum) 이 주어짐
- 선입선출 (FIFO) 방식으로 할당시간(타임 퀀텀)만큼 실행 후 대기 큐로 이동
- 새로운 작업이 도착하면 도착 순서대로 대기 큐에 추가
- 할당 시간이 중요
- 대기큐 + 남은 시간 + 그래프 세 가지를 그리면서 풀어야 함
- 무조건 짧은게 우선이 아니라 큐에 들어간 순서대로 다시 실행되므로 만약 프로세스가 3개면 3개가 번갈아 가면서 실행됨
- 유형 : CPU 사용 순서 / 평균 대기시간 / 평균 반환시간 문제!
- ⭐ 대기 시간 (Waiting Time, WT) = 완료 시간 (FT) - 도착 시간 (AT) - 실행 시간 (BT)
- ⭐ 반환 시간 (Turnaround Time, TAT) = 완료 시간 (FT) - 도착 시간 (AT)
CPU 사용 순서 문제
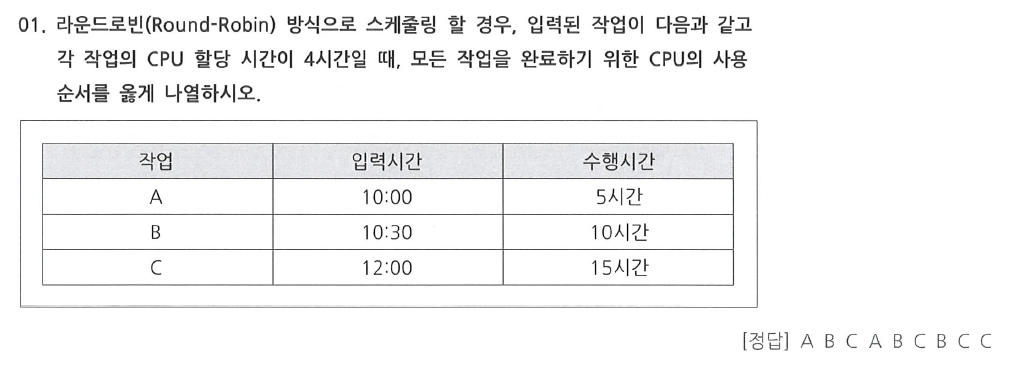
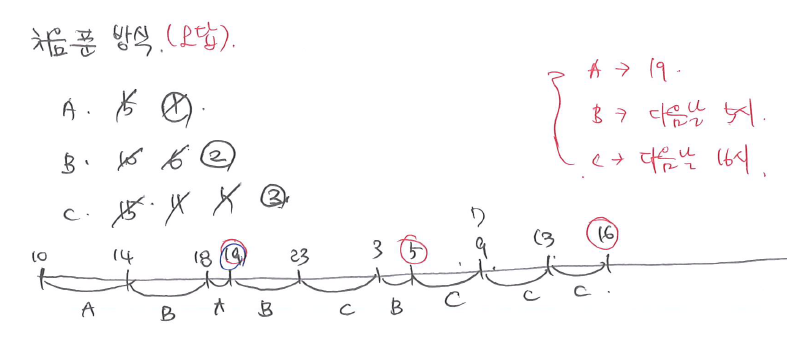
라운드 로빈 방식에서 주의할 점
⭐ 남은 실행 시간만 보고 풀면 틀린다.
⭐ 대기큐를 그려야 한다.
라운드 로빈 (RR) 스케줄링을 풀 때 대기 큐의 순서를 반드시 고려해야 한다. 단순히 "남은 실행 시간"만 보고 짧은 작업을 먼저 실행하는 것이 아니라, 큐에 들어간 순서대로 작업이 실행된다.
타임 퀀텀(시간 할당)이 끝나면 무조건 대기 큐로 이동! → 대기 큐에 있는 순서대로 실행! → 남은 실행 시간이 짧아도 먼저 실행되지 않음 → 그래서 모든 작업이 번갈아가면서 실행됨
라운드 로빈에서는 남은 시간이 적은 작업이 있더라도 먼저 들어온 순서대로 실행된다. 즉, ABC 세 개의 작업이 남아 있다면, ABC 순서대로 계속 번갈아가면서 실행된다. 이걸 놓치면 잘못된 순서로 풀게 되어 답이 틀릴 수 있다.
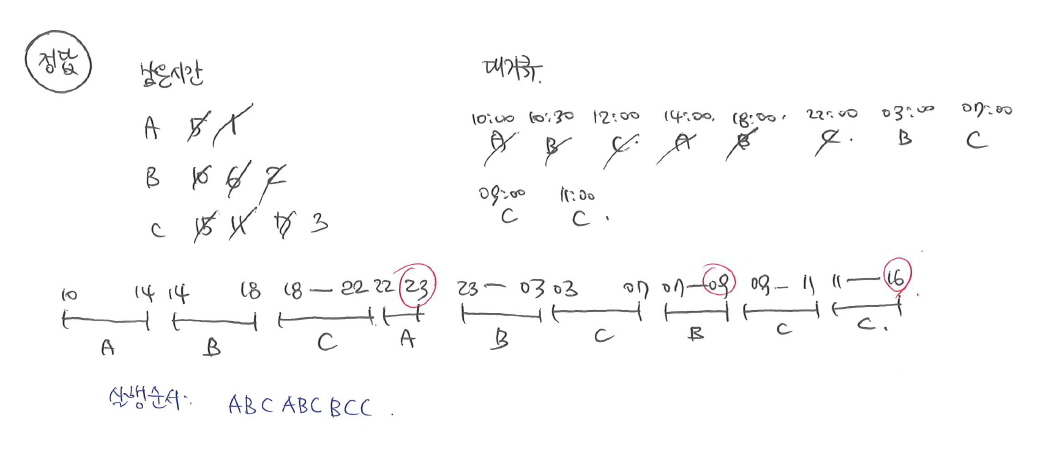
이렇게 풀면 절대 틀리지 않는다.


평균 대기시간 문제
대기 시간 (Waiting Time, WT) = 완료 시간 (FT) - 도착 시간 (AT) - 실행 시간 (BT)


평균 반환시간 문제
반환 시간 (Turnaround Time, TAT) = 완료 시간 (FT) - 도착 시간 (AT)

- 이런 문제는 도착시간이 모두 0이라고 생각하고 푼다 (문제에 따로 명시되지 않았기 때문)





참고 자료
- 흥달쌤의 정보처리기사 계산식 특강
- https://buly.kr/8eljGok
디스크 스케줄링
디스크 스케줄링(Disk Scheduling)이란, 디스크에 요청된 입출력(I/O) 작업들을 효율적으로 처리하기 위해 작업 순서를 정하는 알고리즘
- 디스크는 물리적으로 회전하는 플래터와 이동하는 헤드로 구성된다.
- 따라서 헤드를 이동하는 거리(Seek Time)가 입출력 속도에 큰 영향을 준다.
디스크 스케줄링 종류
- FCFS(First Come First Served)
- SSTF(Shortests Seek Time First)
- SCAN
- C-SCAN
- LOOK
- C-LOOK
- Eschenbach (에셴바흐 기법)
- N-step SCAN
문제풀이
1.FCFS(First Come First Served)
난이도 ⭐
- 초기 헤드위치만 주어짐
- 헤드는 요청 순서대로 움직인다.
- 앞에 초기헤드만 추가하고 요청순서대로 문제풀이
- 이동거리는 절대값(현재위치 - 요청위치)의 합
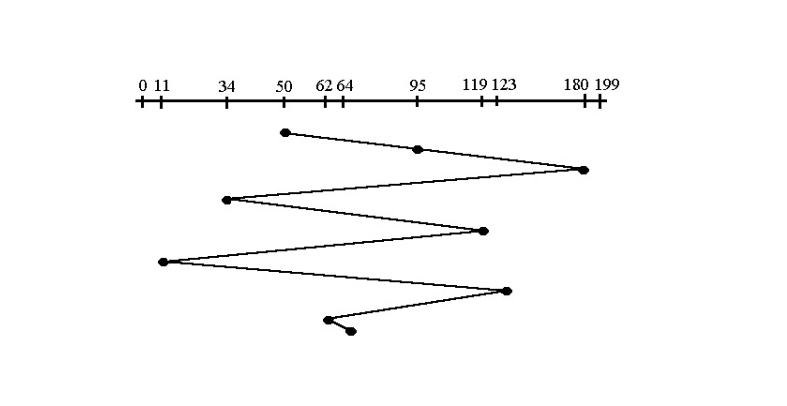

- 초기 헤드 위치: 53
- 대기 큐 순서: 98, 183, 37, 122, 14, 124, 65, 67
- 이동 거리 계산:
1. |53 - 98| = 45
2. |98 - 183| = 85
3. |183 - 37| = 146
4. |37 - 122| = 85
5. |122 - 14| = 108
6. |14 - 124| = 110
7. |124 - 65| = 59
8. |65 - 67| = 2- 총 이동거리: 640 (요청 순서를 그대로 따라간 결과)
45 + 85 + 146 + 85 + 108 + 110 + 59 + 2 = 6402.SSTF(Shortest Seek Time First)
난이도 ⭐
- 초기 헤드위치, 트랙 이동 방향 주어지나 트랙 이동방향은 중요하지 않음
- 초기헤드 위치에서 가장 가까운 트랙을 먼저 처리한다.
- 이후 매 단계마다 남은 요청 중 헤드에 가장 가까운 트랙을 선택한다.
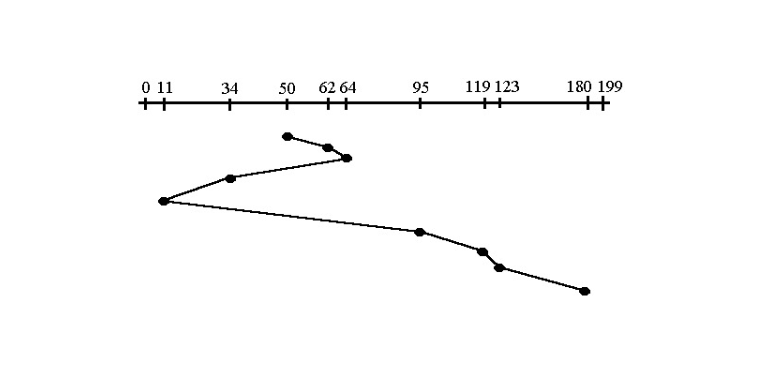

SSTF는 단순하다.
"현재 헤드 위치에서 가장 가까운 트랙을 먼저 처리한다."
- 방향은 “우선순위에 영향을 줄 수 있지만”,SSTF 자체는 방향보다는 "거리"가 가장 중요하다.
- 현재 트랙 50에서 0방향으로 이동 중이다”라는 조건은 SCAN 계열 알고리즘에서는 의미가 크지만,
순수 SSTF에서는 참고 정보일 뿐 실제 결정에 영향을 주지 않음.

- 헤드 시작 위치: 50
- 디스크 범위: 0 ~ 150 (하지만 SSTF에는 직접 영향 없음)
- 대기 큐: 80, 20, 100, 30, 70, 130, 40
- 알고리즘: SSTF
- 목표: 요청들을 모두 처리할 때까지의 총 헤드 이동 거리 구하기
10 (50→40)
+ 10 (40→30)
+ 10 (30→20)
+ 50 (20→70)
+ 10 (70→80)
+ 20 (80→100)
+ 30 (100→130)
= 140- 총 이동거리: 140
10 + 10 + 10 + 50 + 10 + 20 + 30

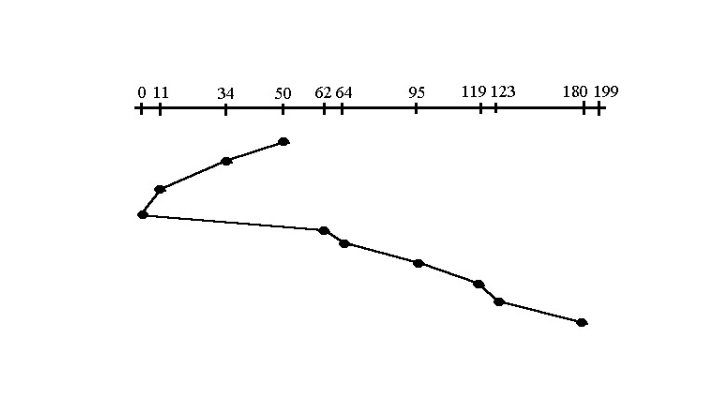
3.SCAN(엘리베이터 알고리즘)
난이도 ⭐⭐
- 초기 헤드위치, 트랙이동방향 주어짐
- 디스크 헤드는 엘리베이터처럼 한 방향으로 이동하면서 요청을 처리하고,
- 끝에 도달하면 방향을 바꿔 되돌아오며 요청을 처리한다.
- SCAN은 반드시 한 쪽 끝(0번 트랙)까지 간다 (C-SCAN도 마찬가지이다.)
- 예: 헤드가 50에서 → 0 방향으로 이동 중이면
→ 50보다 작은 트랙들을 처리하고, 0까지 간 다음(끝까지 간다는게 중요) 방향을 바꿔 50보다 큰 요청들을 처리한다.


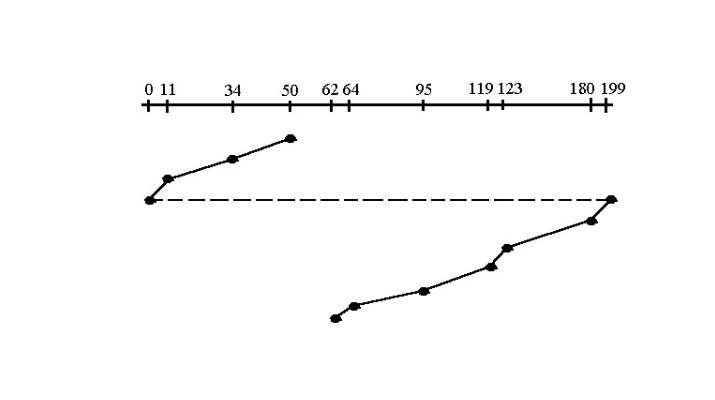
4. C-SCAN(Circular-Scan)
난이도 ⭐⭐⭐
- 초기 헤드위치, 트랙이동방향, 트랙 범위 주어짐
- C-SCAN은 끝까지 갔다가 방향을 바꾸지 않고, 끝에서 반대편으로 "점프"해서 같은 방향으로 다시 처리한다.
- 한 쪽 끝을 찍고 반대쪽 끝까지 간다. 즉, 같은 방향으로만 처리된다.
- C-SCAN은 끝까지 이동하는 것처럼 동작하므로, 요청이 있든 없든 끝까지 도달한 것으로 간주한다.
- 하지만 서비스 순서엔 요청이 있는 트랙만 포함된다.
C-SCAN은 요청이 없는 트랙은 "이동"만 하고 "처리"하지 않는다.
- 문제에서 '처리되는 트랙의 순서'를 물어보면 0을 포함해야 한다.
- 하지만, 헤드는 0까지 이동한 걸로 간주되지만, 0에 요청이 없으므로 → 서비스 순서에 포함되지 않음(서비스 순서 문제에서는 0을 안찍음)

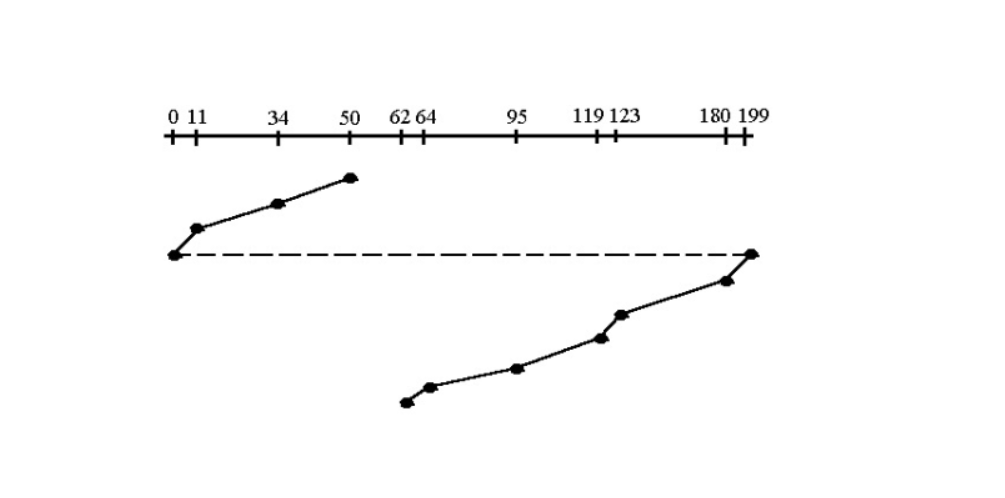
5. LOOK
난이도 ⭐⭐
- 초기 헤드위치, 트랙이동방향 주어짐
- 끝까지 무조건 가지 않고 요청이 있는 마지막 트랙까지만 간다. (요청이 없는 트랙은 스킵한다.)
SCAN vs LOOK
SCAN은 헤드가 끝까지 왕복하며 모든 트랙을 훑고,
LOOK은 요청이 있는 구간까지만 왕복한다.
LOOK vs C-SCAN
LOOK은 요청이 있는 트랙까지만 헤드를 이동시키고 방향을 바꾸며,
C-SCAN은 요청 유무와 관계없이 끝까지 이동한 뒤 반대편 끝으로 점프한다.
LOOK vs C-LOOK
LOOK은 현재 방향으로 요청이 있는 가장 끝 트랙까지 이동 후 방향을 바꾸고,
C-LOOK은 현재 방향으로 요청이 있는 가장 끝 트랙까지 이동한 뒤 반대편 끝으로 점프해 같은 방향으로 계속 진행한다.

6. C-LOOK
난이도 ⭐⭐
- 초기 헤드 위치와 트랙 이동 방향이 주어진다.
- 헤드는 현재 방향으로 요청이 있는 가장 먼 트랙까지 이동한다.
- 끝까지 무조건 가지 않고, 요청이 없는 트랙은 스킵한다.
- 가장 먼 요청을 처리한 뒤에는 반대편 요청이 있는 가장 가까운 트랙으로 점프해서 다시 같은 방향으로 이동하며 처리한다.
- 즉, 방향을 바꾸지 않고, 요청이 있는 구간만 왕복 없이 처리하는 방식이다.

7. Eschenbach(에셴바흐 기법)
헤드가 진행하는 과정에서 각 실린더에 대해 디스크팩의 한 번의 회정 시간 동안만 입출력 요구들을 처리하는 기법이다.
즉, 한 회전 동안 서비스를 받지 못하는 요구들에 대한 처리는 다음으로 미루는 것이다.
이를 위해서는 한 실린더 내의 트랙이나 섹터들에 대한 요구들을 별도로 순서화 하는 메커니즘이 필요하다.
결국, 탐구시간의 최적화와 회전 지연 시간의 최적화를 동시에 추구하는 기본적인 기법인 것이다.
8. N-setp SCAN
SCAN의 무한 대기 발생 가능성을 제거한 것으로 SCAN보다 응답시간의 편차가 적고, SCAN과 같이 진행 방향상의 요청을 서비스하지만, 진행 중에 새로이 추가된 요청은 서비스하지 않고 다음 진행 시에 서비스하는 디스크 스케줄링 기법
참고 자료
- 1억뷰N잡 - 흥달쌤 계산식 특강
LOC 기법
LOC(원시 코드 라인 수, source Line Of Code) 기법
상향식 비용산정 기법으로 프로젝트의 세부적인 작업 단위별로 비용을 산정한 후 집계해서 전체 비용을 산정하는 방법이다.
산정 공식 :
- 노력(인월) = 개발 기간 * 투입 인원
- = LOC / 1인당 월평균 생산 코드 라인 수
- 개발 비용 = 노력(인월) * 단위 비용 (1인당 월평균 인건비)
- 개발 기간 = 노력(인월) / 투입 인원
- 생산성 = LOC / 노력(인월)

참고 자료
- 흥달쌤 계산식 특강
퍼미션, u-mask
1. 퍼미션
리눅스에서 퍼미션(Permission) 이란,
파일이나 디렉터리에 대해 누가 무엇을 할 수 있는지를 지정하는 접근 권한(Access Right) 이다.
1.1 퍼미션 권한 종류
리눅스는 각 파일/디렉토리에 대해 다음 3가지 권한을 설정한다:
권한 | 설명 | 기호 |
|---|---|---|
읽기 (Read) | 파일 내용 보기 / 디렉토리 목록 보기 |
|
쓰기 (Write) | 파일 내용 수정 / 디렉토리에 파일 생성, 삭제 |
|
실행 (Execute) | 파일 실행 / 디렉토리 접근 |
|
1.2 퍼미션의 주체
각 권한은 다음 3가지 사용자 범주에 대해 각각 설정된다:
사용자 | 설명 |
|---|---|
소유자 (User, | 해당 파일을 만든 사용자 |
그룹 (Group, | 파일이 속한 그룹의 사용자 |
기타 (Others, | 그 외 모든 사용자 |
1.3 퍼미션 숫자 표기 (8진수 방식)
권한 | 값 |
|---|---|
| 4 |
| 2 |
| 1 |
조합해서 3자리 숫자로 표시한다:
rwx→ 4+2+1 = 7rw-→ 4+2+0 = 6r--→ 4+0+0 = 4
예: chmod 754 file.txt
→ 사용자: rwx(7), 그룹: r-x(5), 기타: r--(4)
1.4 퍼미션 명령어
명령어 | 설명 |
|---|---|
| 파일의 퍼미션 보기 |
| 퍼미션 변경 ( |
| 소유자 변경 ( |
| 그룹 변경 ( |
1.5 예시
리눅스에서 퍼미션을 바꿀 때 사용하는 chmod 명령어는 두 가지 방식이 있다:
- 1. 기호(Symbolic) 방식:
u+x,g-w등 - 2. 8진수(Numeric) 방식:
644,755등
명령어 + 퍼미션 + 파일명
chmod u+x hello.sh→ 현재 사용자에게 실행 권한 추가
chmod 644 report.txt→ rw-r--r-- 설정 (작성자: 읽기/쓰기, 나머지: 읽기만)
2. U Mask란?
"User File Creation Mask" 의 줄임말이다.
사용자가 새 파일이나 디렉터리를 생성할 때 기본 퍼미션에서 차감할 권한을 지정한다.
2.1 리눅스 기본 생성 권한
- 파일: 기본 최대 권한 =
666(rw-rw-rw-) - 디렉토리: 기본 최대 권한 =
777(rwxrwxrwx)
파일은 기본적으로 실행(x) 권한이 부여되지 않음!
실제 권한=기본 권한−umask 값

참고 자료
- 흥달쌤 계산식 특강
cron, crontab, crond
1. cron
- 리눅스/유닉스의 예약 실행 시스템 이름
- 사용자가 명시한 시간/주기로 자동으로 명령을 실행
- 시스템이 시작되면 자동으로 작동
2. crontab (cron table)
두 가지 의미가 있음:
① 파일
→ 각 사용자별 예약 작업을 저장한 설정 파일
② 명령어
→ crontab 설정을 편집/조회/삭제하는 도구
명령어 | 설명 |
|---|---|
| 현재 사용자 crontab 편집 |
| 현재 사용자 crontab 보기 |
| 현재 사용자 crontab 삭제 |
예: 매일 3시에 백업 실행
0 3 * * * /home/user/backup.sh→ 매일 새벽 3시에 backup.sh 실행
3. crond
- cron 시스템의 데몬 프로세스
- 항상 백그라운드에서 실행 중이며,
- crontab 파일을 읽고, 예약 시간에 맞춰 작업을 수행함
# 데몬 확인
ps -ef | grep crond
# 데몬 시작
sudo systemctl start crond
# 부팅 시 자동 실행 설정
sudo systemctl enable crond- 사용자가
crontab -e로 작업 예약 - 설정 내용이
/var/spool/cron/아래 저장 crond데몬이 해당 내용을 읽고 시간 맞춰 실행
4. crontab Time Format
분 시 일 월 요일 명령어필드 | 의미 | 예시 |
|---|---|---|
분 | 0~59 |
|
시 | 0~23 |
|
일 | 1~31 |
|
월 | 1~12 |
|
요일 | 0~6 (0=일요일) |
|
예시:
30 6 * * 1 /home/user/report.sh→ 매주 월요일 오전 6시 30분에 report.sh 실행
5. crontab Time Format
crontab(크론탭)에서 ,(콤마)와 -(하이픈) 기호는 여러 시간 범위나 개별 값을 지정할 때 사용한다.
기호 | 의미 | 예시 | 설명 |
|---|---|---|---|
| 여러 개의 특정 값 |
| 3, 6, 9시에 실행 |
| 범위 |
| 1 ~ 5 (연속값, 예: 월~금) |
✅ ,(콤마): 여러 개의 특정 값을 지정
콤마는 지정된 여러 값들 각각에 대해 명령어를 실행하라는 뜻이다.
0 9,18 * * * /home/user/task.sh- 매일 오전 9시와 오후 6시(18시) 에 실행
15 1,3,5 * * * /script.sh- 매일 1시 15분, 3시 15분, 5시 15분에 실행
✅ -(하이픈): 범위 지정
하이픈은 연속된 범위를 의미한다.
0 8-11 * * * /home/user/job.sh- 매일 오전 8시, 9시, 10시, 11시에 실행
30 14 * * 1-5 /script.sh- 매주 월~금(1-5) 오후 2시 30분에 실행
