
[Java] 138475 귤 고르기
1.📝 문제
명예의귤 전당(1)
2.
1. 접근방법2.1문제 우선순위큐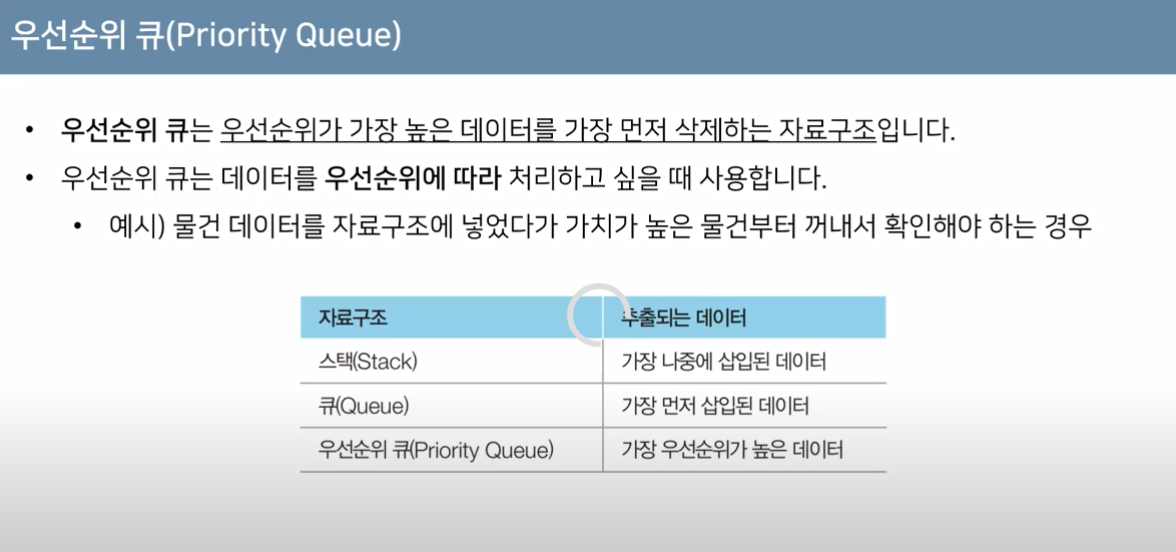
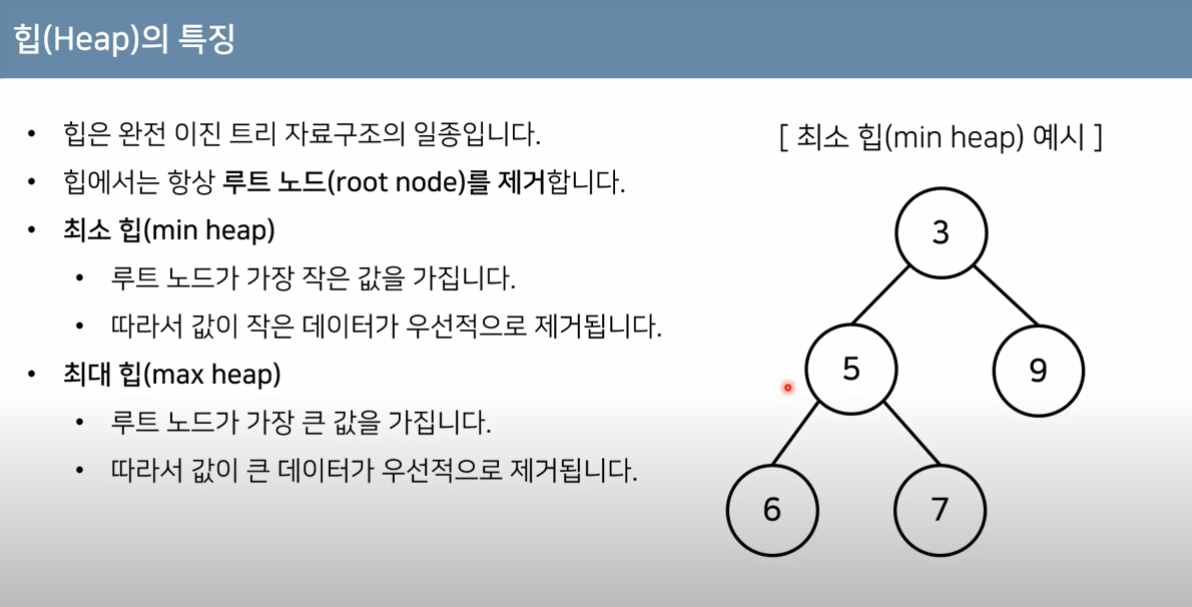
출처: https://www.youtube.com/watch?app=desktop&v=AjFlp951nz0위 그림처럼 힙은 부모-자식 노드 간 우선순위가 유지된 완전이진트리이다. 이 2가지를 만족하면 루트에는 항상 우선순위가 가장 높은 데이터가 있다.배열을 이렇게 취급하면 된다.요약
루트는귤[1]에 있다.N개의 데이터는 [1]~[N]에 차례로 존재한다.현재 노드 i를 기준, 왼쪽 자식 노드: [2i], 오른쪽 자식 노드:[2*i+1]에 있다
2.2 힙 - 우선순위큐 구조
출처: 괭이쟁이님 github블로그
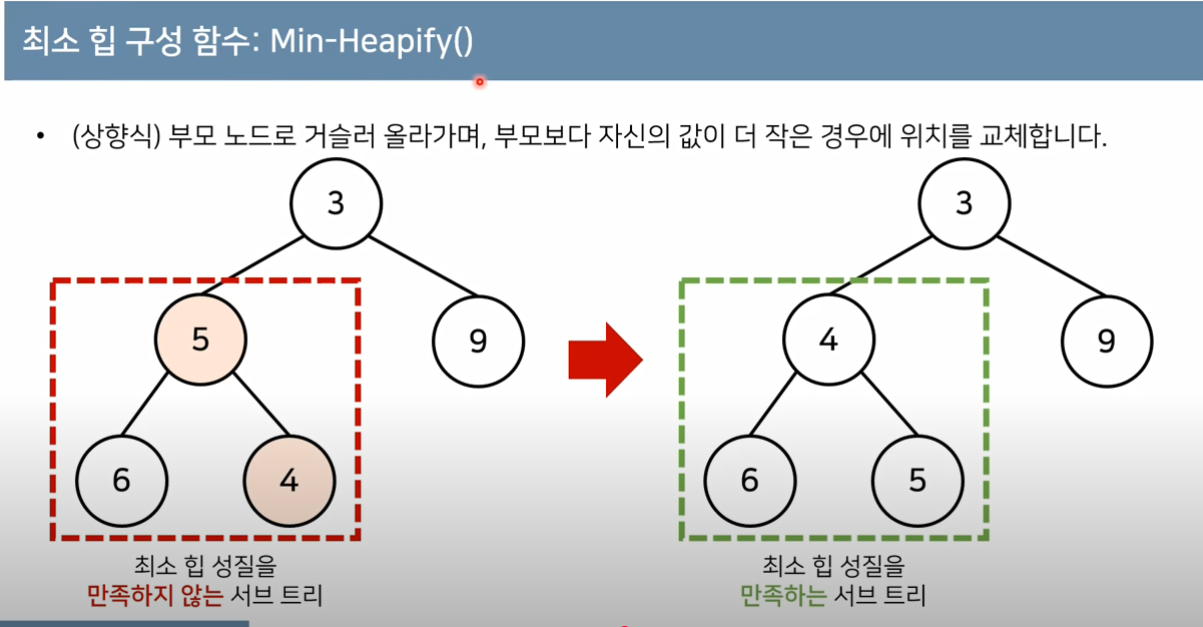
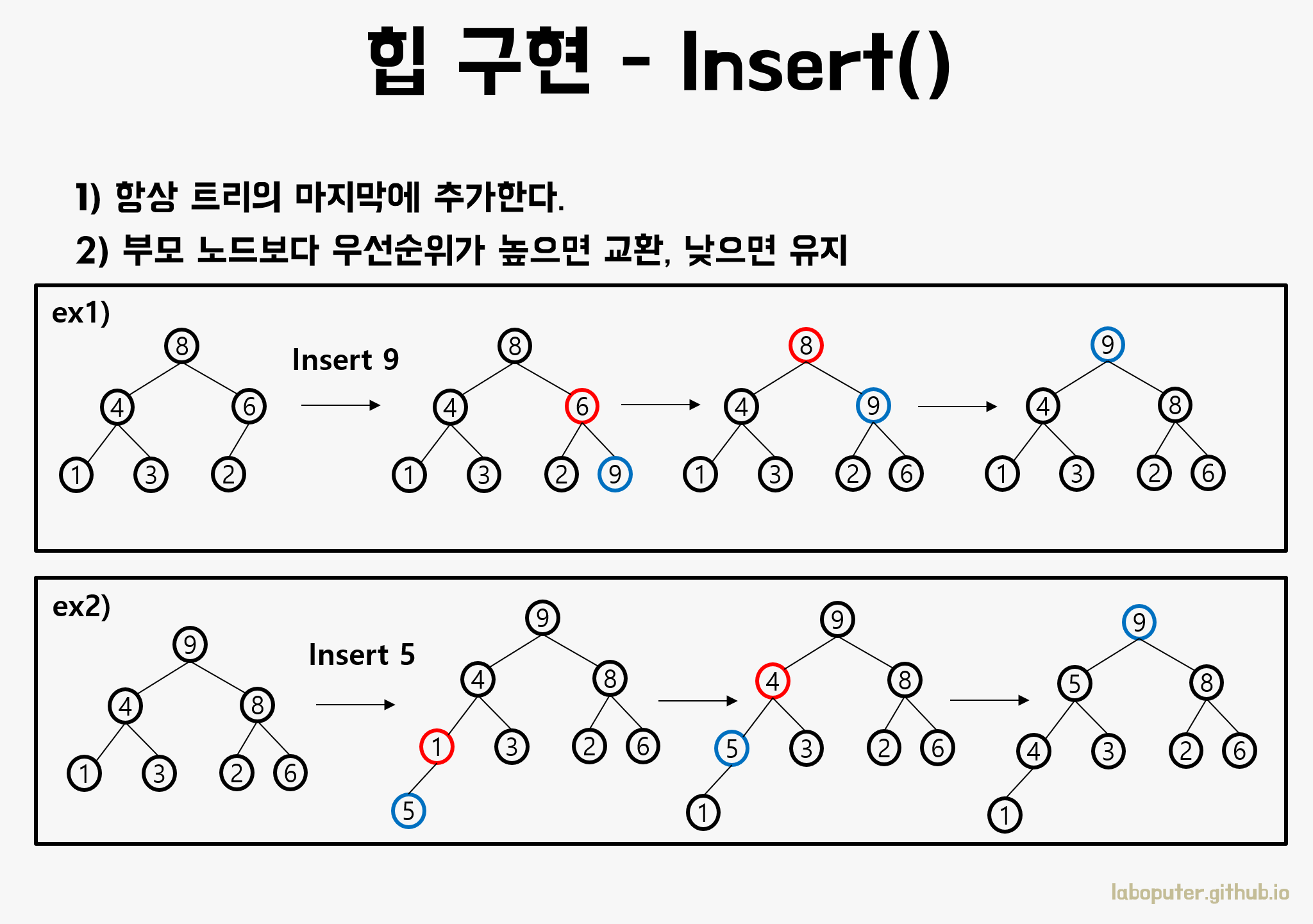
항상 트리의 마지막에 데이터k개를추가추가한 데이터가 부모 노드보다 우선순위가 높으면 교환루트이거나 부모 노드보다 낮을때까지 2를 반복힙은 완전이진트리 때문에 높이는 H = logN 이며, 최악의 경우 루트까지 교환하는 것이므로 시간복잡도는 O(logN)
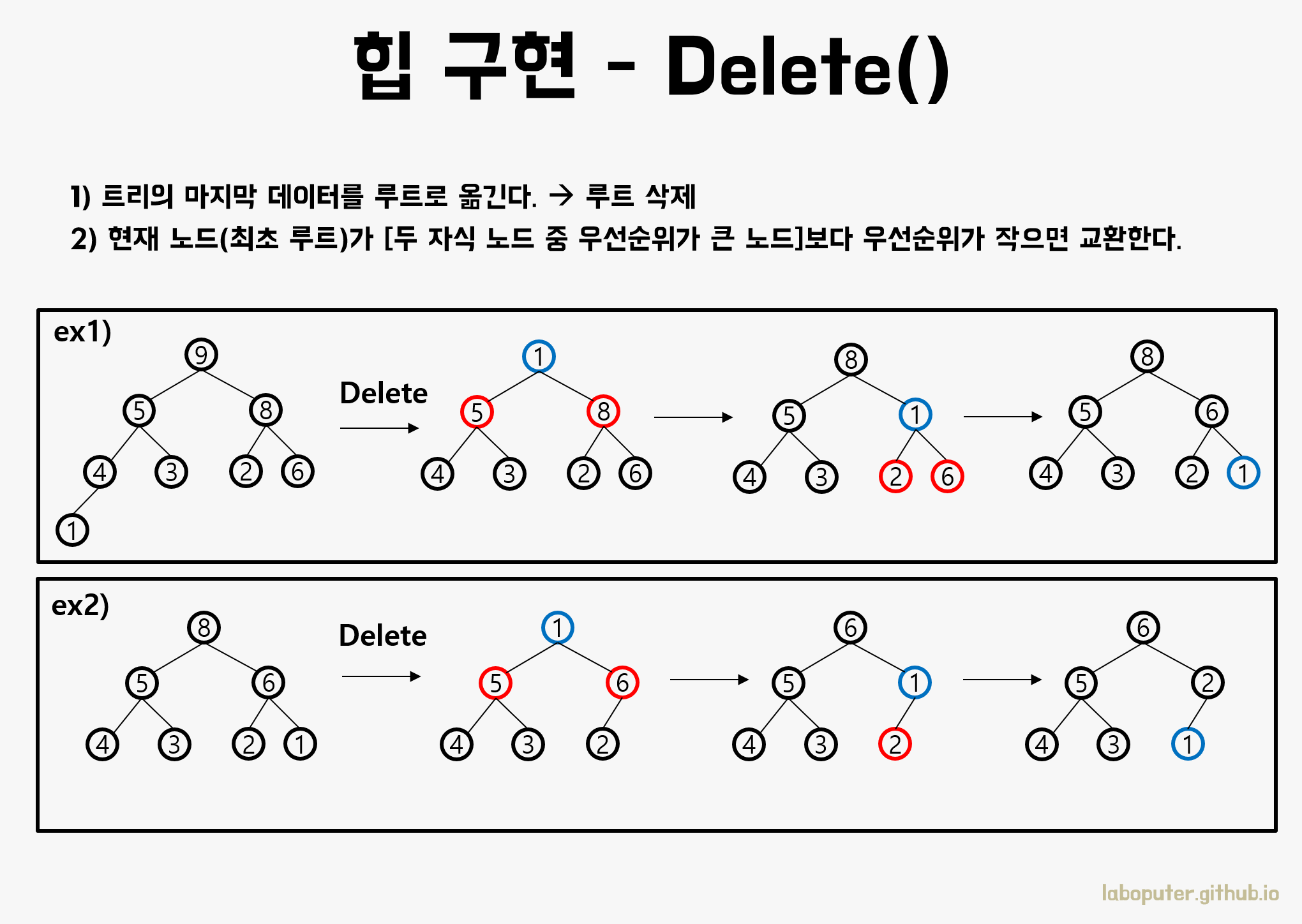
루트고를삭제하고 마지막 노드를 루트로 옮긴다.두 자식노드 중 우선순위가 큰 노드보다 현재 노드가 우선순위가 작으면 교환한다.현재노드가 우선순위가 가장 클때까지 2를 반복한다.
2.3 우선순위 큐 문제
일반 큐(Queue)는 FIFO 구조라 먼저 들어온게 먼저 나가지만 우선순위큐는 우선순위크기가 높은 요소가 먼저 나간다.Java에서는 PriorityQueue 클래스가 있고, 내부적으로 힙(Heap)자료로다른 구현돼종류의 있어서수의 삽입/삭제가 O(log n)으로 효율적이다.
코테에서 대표적으로 쓰이는 상황은 아래와 같다.
- 최
소/최대솟값을반복적으로 빠르게 뽑아야 할 때→ 명예의 전당 문제는 계속 점수가 들어오고, 그 중 가장 낮은 점수를 즉시 알아야 함return 실시간 데이터 처리→ 스트리밍 데이터에서상위 K개 유지하기그리디 알고리즘에서 항상 작은(또는 큰) 값부터 선택하기→ 다익스트라 알고리즘(최단 경로) → 현재가장 짧은 경로노드부터 꺼내야 함→ 허프만 코딩 →가장 빈도가 낮은 문자2개를 반복적으로 꺼내기
3.
2. 정답코드우선순위큐 사용한 코드
import java.util.*;
class Solution {
public int[]int solution(int k, int[] score)tangerine) {
int[]HashMap<Integer, answerInteger> countMap = new int[score.length];
PriorityQueue<Integer> pq = new PriorityQueueHashMap<>(); // 최소 힙
for (int i = 0; i < score.tangerine.length; i++) {
pq.add(score[countMap.put(tangerine[i]);, //countMap.getOrDefault(tangerine[i], 오늘0) 점수+ 추가
// k개 넘으면 가장 낮은 점수 제거
if (pq.size() > k) {
pq.poll()1);
}
// 현재 명예의 전당에서 가장 낮은 점수
answer[i] = pq.peek();
}
return answer;
}
}매번 점수를 넣고정렬한 뒤k개까지만 유지가장 낮은 점수 answer[i]에 넣기
내가 푼 코드
생각나는 대로 풀었는데 ArrayList + sort를 사용했다. 이렇게 하면 매일 정렬하기 때문에 조금 비효율적이라고 한다. 코드는 돌아가는데 원칙적으로는 PriorityQueue(우선순위큐)를 쓰면 삽입/삭제가 더 효율적이라고 한다.보통 정렬 알고리즘의 시간 복잡도는 O(n log n)이다. 입력 크기(n)만큼 다 돌면서 그 안에서 log n만큼 비교하는 구조이다. 이렇게 하면 입력이 커질수록 시간 복잡도가 증가하고 매우 느리다. 반면 이진 탐색이나 힙에서 삽입/삭제 하는 경우 시간 복잡도는 O(log n)이다. 입력 크기 n이 커져도 거의 증가하지 않는다. 입력이 백만 배 커져도 연산 횟수가 20배 정도밖에 차이 안 난다.
import java.util.*;
class Solution {
public int[] solution(int k, int[] score) {
// k일 다음부터는 출연가수 점수가 기존 명전 가수 k번째보다 높으면 너나가
// 매일 가장 점수가 낮은 사람을 리턴
int[] answer = new int[score.length];
ArrayListList<Integer> rankListcounts = new ArrayList<>(countMap.values());
//counts.sort(Collections.reverseOrder());
그럼int 삽입picked 삭제가= 자유로운0;
거int -kinds = 0;
for (int c : counts) {
picked += c;
kinds++;
if (picked >= ArrayListk) //break;
길이}
k의return ArrayList만들kinds;
}
}3. 설명
- 해시맵에 귤의 종류, 개수를 매핑한다.
- 귤의 개수를 담을 List count를 선언하고
//내림차순 정렬한다. - 고른
후귤 개수, 종류를 담을 변수 picked, kinds 를 선언한다. - count를 하나씩 순회하며 picked에 갯수를 누적하고, 종류+1을 한다.
- 만약 고른 귤 개수가
장낮은k보다 크거나리턴같으면for멈춘다.
4. 오답 / 어려웠던 점
- ArrayList만들고 map의 밸류와 매핑하는 법 new ArrayList<>(
int i = 0; i < score.length; i++countMap.values(){ rankList.add(score[i]); - 오름차순 정렬 Collections.sort(
rankList, Collections.reverseOrder()); //counts) - 내림차순 정렬
// 이 때 k개씩 끊은거 어떻게 처리? // rankList 길이가 k보다 크면 if (rankList.size(counts.sort(Collections.reverseOrder()> k) { rankList.remove(rankList.size()- 1); // 제일 낮은 점수 제거하기 } // 현재 명예의 전당에서 가장 낮은 점수 answer[i] = rankList.get(rankList.size() - 1); } return answer; } }