
[SQL] 133027 주문량이 많은 아이스크림들 조회하기
https://school.programmers.co.kr/learn/courses/30/lessons/133027
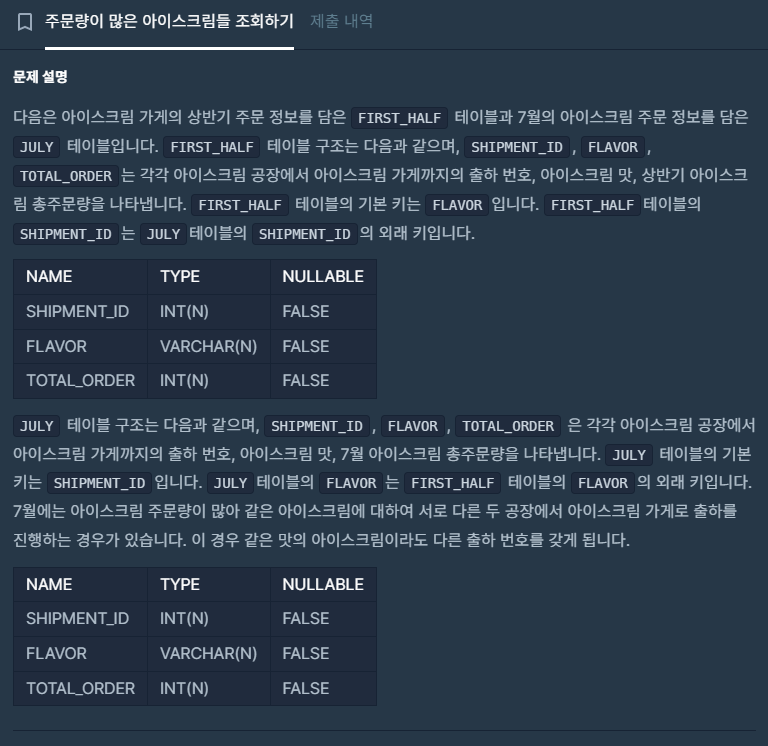
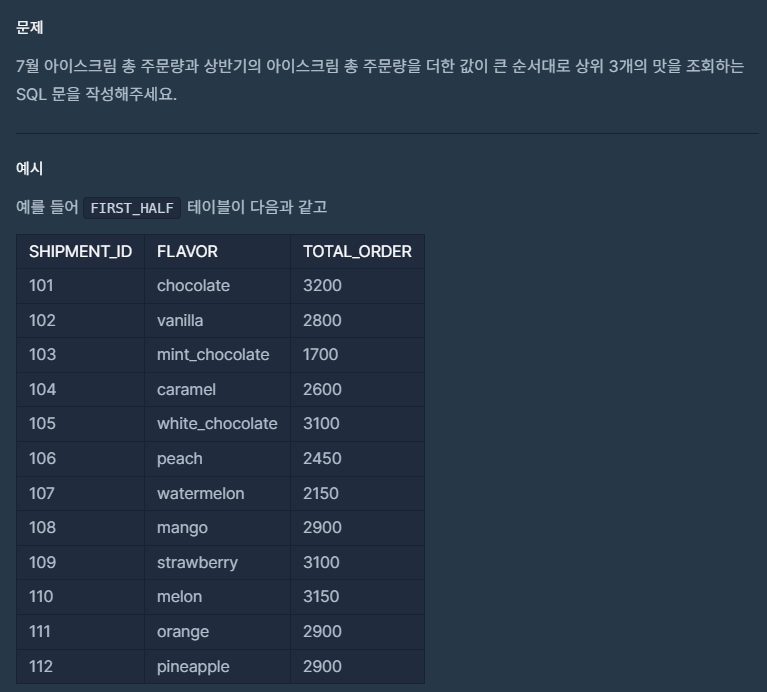
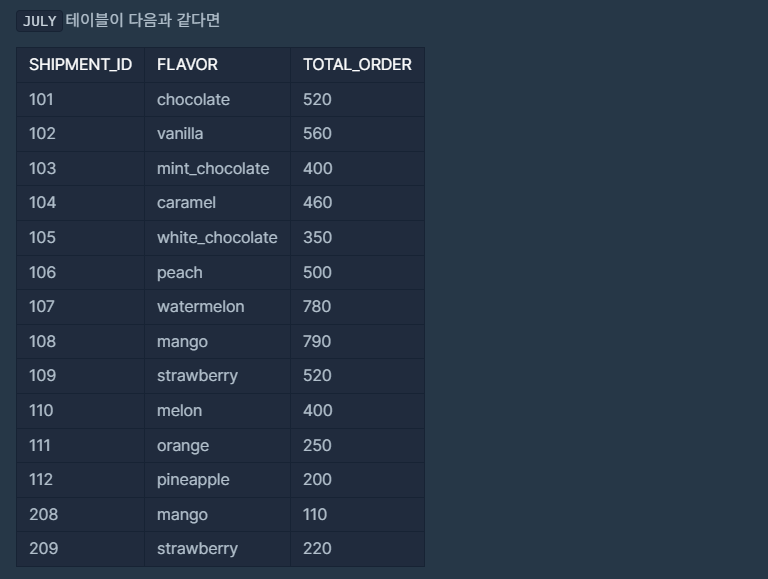
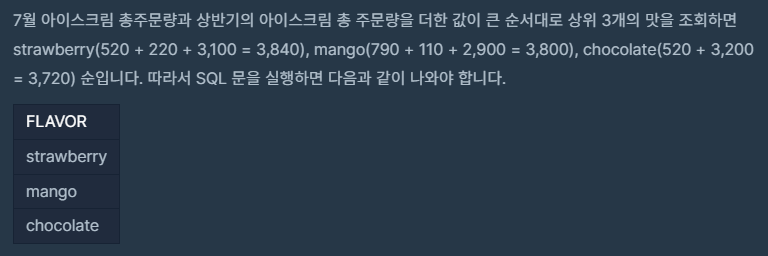
📌문제
- FLAVOR별로 상반기 주문량과 7월 주문량 전체 합을 합산
- 이 합산 값을 기준으로 내림차순 정렬
- 상위 3개 맛(FLAVOR) 조회
💡 정답 쿼리
Subquery + UNION ALL 방식으로 개선한 쿼리
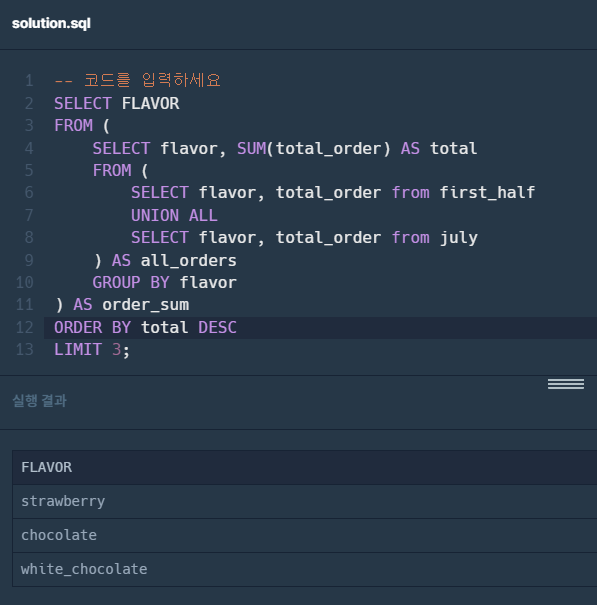
SELECT FLAVOR
FROM (
SELECT flavor, SUM(total_order) AS total
FROM (
SELECT flavor, total_order FROM first_half
UNION ALL
SELECT flavor, total_order FROM july
) AS all_orders
GROUP BY flavor
) AS order_sum
ORDER BY total DESC
LIMIT 3;FROM절에 서브쿼리 이중으로 사용 : 두 테이블에서FLAVOR,TOTAL_ORDER컬럼만 뽑아UNION ALL로 합침SELECT FLAVOR
→ 최종 결과로 맛(FLAVOR)만 출력하기FROM ( ... ) AS order_sum
→ 상반기와 7월 주문량을 합쳐 맛별로 총합을 구한 서브쿼리로부터 데이터 가져오기SELECT flavor, SUM(total_order) AS total
→flavor별로total_order를 모두 더하여 총 주문량(total)을 계산하기FROM ( ... ) AS all_orders
→first_half와july테이블의 데이터를 합친 서브쿼리를 대상으로 한다.SELECT flavor, total_order FROM first_half
→first_half테이블에서 맛과 주문량 컬럼만 고른다.UNION ALL SELECT flavor, total_order FROM july
→july테이블에서 맛과 주문량을 선택하고, 중복 제거 없이 그대로 합치기GROUP BY flavor
→ 같은 맛끼리 묶어서 주문량 집계ORDER BY total DESC
→ 맛별 총 주문량이 많은 순으로 내림차순 정렬LIMIT 3
→ 가장 주문량이 많은 상위 3개의 맛만 출력
가장 안쪽 서브쿼리
SELECT flavor, total_order FROM first_half
UNION ALL
SELECT flavor, total_order FROM julyfirst_half,july테이블에서FLAVOR,TOTAL_ORDER컬럼만 선택UNION ALL사용 → 두 테이블의 데이터를 중복 제거 없이 단순히 합침
→ 결과: 전체 주문 기록을 담은 하나의 테이블처럼 사용 (all_orders)
바깥쪽 서브쿼리
SELECT flavor, SUM(total_order) AS total
FROM ( ... ) AS all_orders
GROUP BY flavor- 안쪽에서 합친 데이터를 바탕으로, 각 아이스크림 맛(
flavor)별로 주문량을 합산
→ 결과: 각 맛마다 총 주문량이 담긴 테이블 생성 - 이 결과에 별칭
order_sum부여 → 바깥 쿼리에서 사용
GROUP BY절
flavor값이 같은 행들을 묶어줌
→ 묶인 그룹 내에서SUM(total_order)로 총 주문량 계산
❌ 오답정리
LEFT OUTER JOIN 방식
처음에는FIRST_HALF에 있는 맛을 기준으로 두 테이블을 LEFT JOIN 해서 JULY의 주문량과 합치는 코드를 짰다.
이렇게 짜다 보니 코드가 복잡해졌다.
- 필터: 따로 필터링(WHERE 조건)은 없고, 모든 데이터를 대상으로 계산한다.
JOIN조건: FLAVOR 기준으로 LEFT JOIN을 해서 상반기 데이터에 7월 데이터를 붙인다.
→ 7월에 주문이 없었던 맛도 포함되도록 LEFT JOIN이 적절하다.- 상반기 주문량 계산:
FIRST_HALF.TOTAL_ORDER
→ 이미 각 맛(FLAVOR)별로 집계된 주문량이므로 그대로 사용한다. - 7월 주문량 계산 :
JULY테이블은 같은 맛이라도 출하 번호(SHIPMENT_ID)가 다르면 여러 행으로 되어 있음
→ 따라서 FLAVOR별로 GROUP BY해서 SUM을 먼저 구해야 한다. - 총합 계산 : 두 테이블을 FLAVOR 기준으로 JOIN하고
→FIRST_HALF.TOTAL_ORDER + JULY_TOTAL로 계산한다. GROUP BY는FLAVOR기준이다.ORDER BY는총합(상반기 + 7월)기준으로 내림차순
→ 상위 3개만 추출
이렇게 했을 때 코드가 길어지고 성능 떨어지는 이유는 아래와 같다.
SELECT
FH.FLAVOR,
(IFNULL(FH.TOTAL_ORDER, 0) + IFNULL(J.TOTAL_ORDER, 0)) AS TOTAL
FROM FIRST_HALF FH
LEFT JOIN (
SELECT FLAVOR, SUM(TOTAL_ORDER) AS TOTAL_ORDER
FROM JULY
GROUP BY FLAVOR
) J
ON FH.FLAVOR = J.FLAVOR
UNION
SELECT
J.FLAVOR,
J.TOTAL_ORDER
FROM (
SELECT FLAVOR, SUM(TOTAL_ORDER) AS TOTAL_ORDER
FROM JULY
GROUP BY FLAVOR
) J
LEFT JOIN FIRST_HALF FH
ON FH.FLAVOR = J.FLAVOR
WHERE FH.FLAVOR IS NULL
ORDER BY TOTAL DESC
LIMIT 3;1. 첫 번째 SELECT (LEFT JOIN)
FIRST_HALF에 있는 맛을 기준으로JULY의 주문량을 합친다.JULY는FLAVOR기준으로 집계(SUM)되어야 함 (같은 맛에 여러SHIPMENT_ID가 있을 수 있음).IFNULL을 사용하여JULY에 없는 맛의 경우 0으로 처리한다.
2. 두 번째 SELECT (LEFT JOIN + IS NULL)
JULY에는 존재하지만FIRST_HALF에는 없는 맛을 별도로 조회한다.- 이 경우엔
FIRST_HALF가 NULL이므로FLAVOR IS NULL조건을 줘서 누락된 맛만 추출한다.
3. UNION으로 두 결과를 합치고, ORDER BY로 총합 기준 내림차순 정렬 + LIMIT 3.
4. 결론
- 조인을 쓸 경우 누락되는 데이터가 없도록 OUTER JOIN이 필요하다.
JULY에는 같은 맛이 여러 행으로 있을 수 있어GROUP BY와SUM()이 필수이다.IFNULL또는COALESCE를 이용해 NULL값은 0으로 처리해야 합산이 정확해진다.JOIN보다SUBQUERY+UNION ALL을 쓰는 것이 간결하고 가독성이 높으며 성능이 좋다.
JOIN < Subquery 인 이유
1. 복잡도와 간결성
UNION ALL- 두 테이블에서
FLAVOR와TOTAL_ORDER컬럼을 단순히 쭉 합친 뒤,GROUP BY FLAVOR로 합산하는 매우 직관적이고 간단한 방법이다. 코드도 훨씬 짧고 이해하기 쉽다.
- 두 테이블에서
JOINJULY테이블은 같은 맛에 대해 여러 출하번호가 있으므로 먼저GROUP BY해서 합산해야 하고,- 두 테이블을 외부 조인으로 합치고,
IFNULL처리도 해야 하며, 누락되는 맛을 찾기 위한 별도의 쿼리도 필요해서 쿼리가 훨씬 복잡해진다.
2. 성능 측면
UNION ALL+ GROUP BY- 한 번에 합쳐서
GROUP BY하면 MySQL이 내부적으로 효율적인 집계 연산을 수행한다. - 단순히 모든 데이터를 합치는 방식이라 인덱스도 잘 활용 가능합니다.
- 한 번에 합쳐서
JOIN+ GROUP BY + 여러 서브쿼리- 먼저
JULY를 집계하고, 그걸 다시FIRST_HALF와 조인하고, - 누락된 데이터도 따로 처리하는 로직은 쿼리 플랜이 복잡해지고 처리 비용도 상대적으로 높다.
- 먼저
3. 데이터 특성
JULY테이블은 같은 맛에 대해 여러 출하번호가 존재할 수 있으므로,JOIN은 먼저 집계 후 조인해야 하는 반면,UNION ALL은 원본 데이터 모두를 다 합친 뒤 그룹바이 하기 때문에 데이터 누락 가능성이 없다.
4. 가독성 & 유지보수
UNION ALL+ GROUP BY가 훨씬 간단해서 나중에 다른 기간 데이터를 더 추가하거나 조건을 바꿀 때 확장하기 쉽다.
JOIN vs SUBQUERY vs WITH
각각 언제 써야 성능 좋은지 비교
나중에