
[SQL] 59413 입양 시각 구하기 (2)
https://school.programmers.co.kr/learn/courses/30/lessons/59413
1. 문제
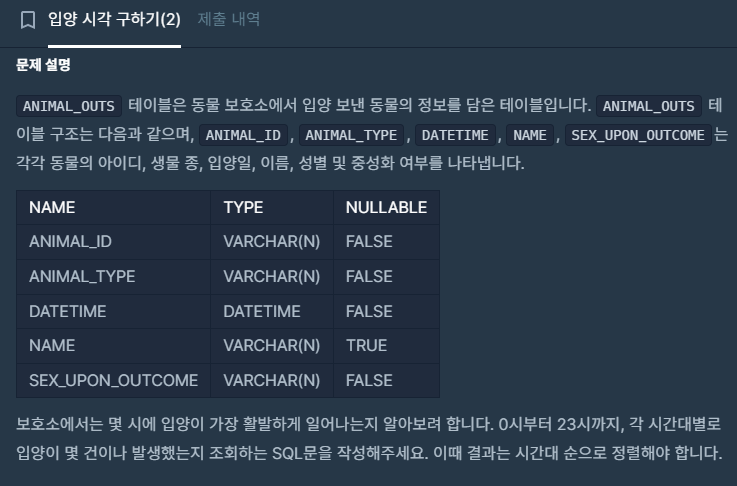
테이블
- ANIMAL_OUTS(ANIMAL_ID, ANIMAL_TYPE, DATETIME, NAME, SEX_UPON_OUTCOME)
조건
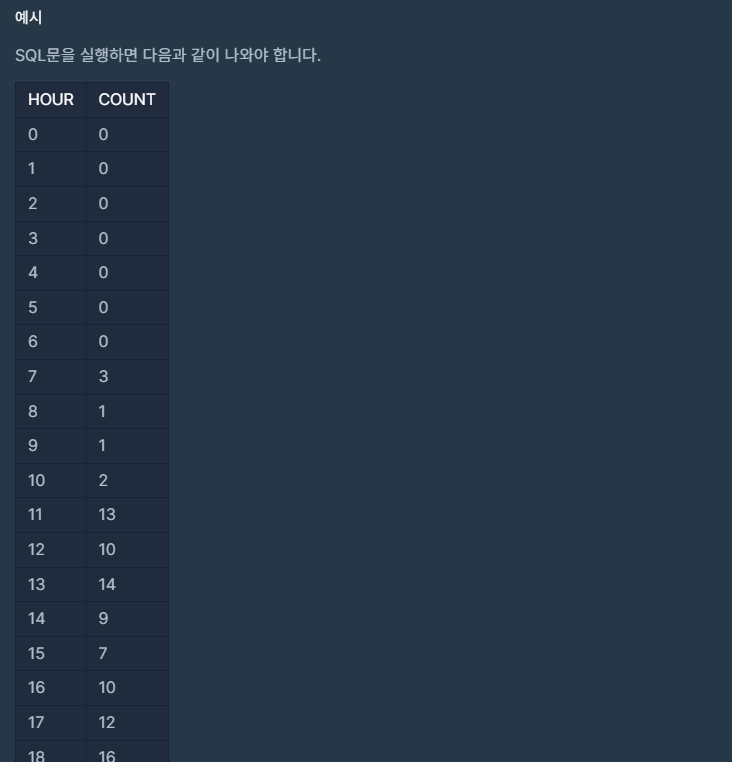
- 0시부터 23시까지 각 시간대별 입양 건수(COUNT) 구하기
- 입양이 없는 시간대는 0으로 표시
- 결과는 시간대(HOUR) 순서대로 정렬
- DATETIME 컬럼에서 시간만 추출해서 계산
2. 오답쿼리
2.1 첫번째 시도
입양 기록이 0건인 시간대 누락
-- 코드를 입력하세요
SELECT HOUR(DATETIME) AS HOUR, COUNT(*) AS COUNT
FROM ANIMAL_OUTS
GROUP BY HOUR(DATETIME)
ORDER BY HOUR(DATETIME)처음에 작성한 SQL문이 틀린 이유는 0~23시 중 입양이 없는 시간대도 결과에 포함되어야 하는데, 아래와 같이 출력결과 입양 데이터가 있는 시간만 나오기 때문이다. GROUP BY는 기본적으로 존재하는 데이터만 집계해서, 입양 기록이 없는 시간대는 결과에 안 나타난다고 한다.
문제 예시처럼 0건도 표시하려면 시간 범위를 만들어서 LEFT JOIN해야 한다.
LEFT JOIN하면 대상이 되는 테이블의 데이터는 모두 출력되기 때문이다.
2.2 두 번째 시도
변수 @HOUR를 하나씩 증가시키면서 서브쿼리로 COUNT를 뽑는 방식
SET @HOUR = -1;
SELECT (@HOUR := @HOUR + 1) AS HOUR,
(SELECT COUNT(HOUR(DATETIME))
FROM ANIMAL_OUTS
WHERE HOUR(DATETIME)=@HOUR) AS COUNT
FROM ANIMAL_OUTS
WHERE @HOUR < 23;FROM ANIMAL_OUTS를 붙여서 사실상 테이블의 행 수만큼 루프가 도는 구조라 불필요하게 많이 반복된다.WHERE @HOUR < 23조건도 테이블 행마다 검사하기 때문에 중복된 결과가 나올 수 있다.- 서브쿼리에서
COUNT(HOUR(DATETIME))대신COUNT(*)가 더 안전하다.
따라서 아래와 같이 변수 + 서브쿼리에 LIMIT 방식으로 바꾸면 성능이 좀 낫다고 한다.
SET @HOUR := -1;
SELECT @HOUR := @HOUR + 1 AS HOUR,
(SELECT COUNT(*)
FROM ANIMAL_OUTS
WHERE HOUR(DATETIME) = @HOUR) AS COUNT
FROM information_schema.COLUMNS
LIMIT 24;3. 정답쿼리
입양 시각 구하기 문제는 크게 세 가지 방법으로 해결할 수 있다고 한다.
- UNION ALL 방식
- 변수(@HOUR) 방식 - 루프 흉내
- WITH RECURSIVE 방식 (MySQL 8 이상) - 추천
3.1 UNION ALL 방식 (MySQL 5.x에서도 가능)
WITH hours AS (...)로 0~23시를 만들어서 모든 시간대 포함하기LEFT JOIN으로 입양 기록과 연결, 기록이 없으면NULLCOALESCE로 NULL을 0으로 변환하기GROUP BY후ORDER BY로 시간순 정렬
SELECT h AS HOUR,
COALESCE(COUNT(a.DATETIME), 0) AS COUNT
FROM (
SELECT 0 AS h UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3
UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7
UNION ALL SELECT 8 UNION ALL SELECT 9 UNION ALL SELECT 10 UNION ALL SELECT 11
UNION ALL SELECT 12 UNION ALL SELECT 13 UNION ALL SELECT 14 UNION ALL SELECT 15
UNION ALL SELECT 16 UNION ALL SELECT 17 UNION ALL SELECT 18 UNION ALL SELECT 19
UNION ALL SELECT 20 UNION ALL SELECT 21 UNION ALL SELECT 22 UNION ALL SELECT 23
) AS hours
LEFT JOIN ANIMAL_OUTS a
ON h = HOUR(a.DATETIME)
GROUP BY h
ORDER BY h;COALESCE(COUNT(a.DATETIME), 0)→ “없으면 0으로 표시”SELECT 0 AS h→ “시간 숫자(0)를 만들고 열 이름을 h라고 붙임”
UNION ALL 이 길어서 가독성이 좀 떨어지긴 하지만 이렇게 하면 MySQL버전에 상관 없이 동작한다.
NULL 처리
1️⃣ COALESCE(COUNT(a.DATETIME), 0) AS COUNT
COUNT(a.DATETIME)
- 특정 시간대에 입양된 동물 수를 세는 것이다.
- LEFT JOIN을 했을 때 해당 시간대에 입양이 1건도 없으면 NULL이 떨어질 수 있기 때문임..
COALESCE(값, 대체값)
- 첫 번째 값이 NULL이면 두 번째 값을 대신 반환한다.
- 즉, COUNT(a.DATETIME)이 NULL일 경우 0으로 바꿔주는 함수이다.
UNION ALL 연산
2️⃣ SELECT 0 AS h
이 부분은 시간 숫자를 강제로 만들어내는 코드이다.
SELECT 0 AS h→ 실행하면 결과가 이렇게 나온다.
h |
|---|
0 |
여기에다가
SELECT 0 AS h UNION ALL SELECT 1 UNION ALL SELECT 2→ 실행하면
h |
|---|
0 |
1 |
2 |
이렇게 0, 1, 2… 숫자 목록을 인위적으로 만들어서 ANIMAL_OUTS 테이블과 JOIN할 수 있는 발판을 만드는 것이다.
즉, "0시, 1시, 2시 … 23시"라는 모든 시간대를 강제로 생성해주는 역할이다.
3.2 변수(@HOUR) 방식 (루프 흉내)
SET @HOUR := -1;→ 변수 준비SELECT @HOUR := @HOUR + 1 AS HOUR ... LIMIT 24;
→@HOUR가 0 → 1 → 2 … → 23까지 자동 증가(SELECT COUNT(*) FROM ANIMAL_OUTS WHERE HOUR(DATETIME) = @HOUR)
→ 해당 시간대의 입양 건수를 세서 결과에 붙임
SET @HOUR := -1;
SELECT @HOUR := @HOUR + 1 AS HOUR,
(SELECT COUNT(*)
FROM ANIMAL_OUTS
WHERE HOUR(DATETIME) = @HOUR) AS CNT
FROM (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4
UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8
UNION ALL SELECT 9 UNION ALL SELECT 10 UNION ALL SELECT 11 UNION ALL SELECT 12
UNION ALL SELECT 13 UNION ALL SELECT 14 UNION ALL SELECT 15 UNION ALL SELECT 16
UNION ALL SELECT 17 UNION ALL SELECT 18 UNION ALL SELECT 19 UNION ALL SELECT 20
UNION ALL SELECT 21 UNION ALL SELECT 22 UNION ALL SELECT 23 UNION ALL SELECT 24) AS tmp;- 코드가 짧아서 확실히
UNION ALL보다 깔끔하다. information_schema.COLUMNS같은 시스템 테이블을 이용해서 24번만 루프를 돌리는 원리이다.- 데이터량과 관계없이 항상 24행 결과를 보장한다.
- 하지만 변수 사용이 낯설어서 나같은 초보자가 이해하기 어렵다.
- 나도 SQL에서 이렇게 변수를 선언하는 걸 오답정리 하면서 처음 보았다.
1️⃣ SET @HOUR := -1;
- 여기서
@HOUR는 사용자 변수(User-defined variable)이다. - MySQL에서
@로 시작하는 건 세션 단위 변수라서 쿼리 실행하는 동안만 살아 있다고 한다. SET @HOUR := -1;은@HOUR라는 변수를-1로 초기화한다는 뜻이다.- "이제부터
@HOUR라는 이름의 변수를 만들고 값은 -1로 넣어둘게" 라고 이해하면 쉽다.
2️⃣ := 연산자
MySQL에서는 =도 대입 연산자로 쓰이지만, :=을 쓰는 게 더 명확하게 “값을 변수에 대입한다”는 의미라고 한다.
SET @num := 10;→ 변수 @num에 10을 넣어라.
3️⃣ @HOUR := @HOUR + 1 AS HOUR
- 이건 실행할 때마다
@HOUR값을 1씩 증가시키는 트릭이다. - 처음에
@HOUR = -1로 세팅했으니까, 첫 번째 실행에서@HOUR := -1 + 1 = 0→ 결과 HOUR = 0 - 두 번째 실행에서
@HOUR := 0 + 1 = 1→ 결과 HOUR = 1 - … 이렇게 계속 올라가서 23까지 출력된다.
- 그래서
LIMIT 24를 붙여서 딱 0~23까지만 나오게 하는 것이다.
3.3 WITH RECURSIVE 방식 (MySQL 8 이상)
WITH RECURSIVE hours AS (
SELECT 0 AS HOUR
UNION ALL
SELECT HOUR + 1 FROM hours WHERE HOUR < 23
)
SELECT h.HOUR,
COALESCE(COUNT(a.DATETIME), 0) AS COUNT
FROM hours h
LEFT JOIN ANIMAL_OUTS a
ON h.HOUR = HOUR(a.DATETIME)
GROUP BY h.HOUR
ORDER BY h.HOUR;MySQL 8 이상에서만 지원하는 방식인데, 변수를 선언하지 않고도 숫자를 재귀적으로 자동 생성할 수 있어서 가장 깔끔하다. WITH RECURSIVE는 재귀적 CTE(Common Table Expression)를 만드는 구문이다. 즉, 임시 테이블(hours)을 만들고 그 안에서 자기 자신을 다시 참조하면서 반복적으로 데이터를 생성한다. MySQL 버전이 낮지 않으면 가장 추천되는 깔끔한 방식이라고 한다.
자바 for문을 떠올리면 이해하기 쉽다. “0부터 시작해서 1씩 증가시키며 23까지 숫자 목록을 만들어라” 라는 로직을 SQL로 옮겨놓은 것과 같다.
1️⃣ WITH RECURSIVE hours AS (...)
WITH RECURSIVE는 재귀적 CTE(Common Table Expression)를 만든다는 뜻이다.- 즉, 임시 테이블(
hours)을 만들고, 그 안에서 자기 자신을 다시 참조해서 반복적으로 데이터를 생성할 수 있어다.
2️⃣ SELECT 0 AS HOUR
- 재귀의 시작(Anchor part)이다.
- 여기서
0이라는 값을 하나 만들고, 그 열 이름을HOUR라고 붙인다. - 결과:
HOUR |
|---|
0 |
3️⃣ UNION ALL
- 첫 번째 결과(0)와 뒤에 나오는 재귀 쿼리 결과를 합친다.
UNION은 중복 제거를 하지만,UNION ALL은 중복도 다 포함시킨다.- 여기서는 중복 걱정 없으니까
UNION ALL을 쓰는 게 빠르고 안전하다.
4️⃣ SELECT HOUR + 1 FROM hours WHERE HOUR < 23
- 재귀 부분(Recursive part)이다.
- 방금 만든
hours임시 테이블에서HOUR값을 하나씩 꺼내서+1을 해줌 - 그리고
WHERE HOUR < 23조건으로 23까지만 생성되게 제한한다.
동작 흐름을 보자:
- 처음에는
0이 나옴 (Anchor part) hours테이블에0이 있으니 →0+1=1생성hours테이블에1이 있으니 →1+1=2생성- … 반복 …
23까지 오면23 < 23조건이 false → 멈춤
→ 여기서 <24가 아니라 <23까지 해야 23시까지 출력되다는 것이 약간 헷갈린다.- 이 과정을 다 거치면
hours라는 CTE에는 0부터 23까지 숫자가 생긴다.